クラスタリング
機械学習の一種で膨大なデータを類似度に応じて分類するアルゴリズム。データに対して特徴を見いだし、自動で分類するため、ビッグデータの分析や解析に活用されている。

データを効率的に分類、AI時代に必要な技術
昨今は新型コロナウイルス感染拡大に伴い、ニュースなどでクラスタという言葉を耳にする機会が増えましたが、クラスタリングと語源は同じで、群れや集団を意味します。クラスタの発生により感染が集中的に起こり、その患者集団となるクラスタを早期に発見することが感染拡大を防ぐ対策の一つとなっています。
それに対してAI(人工知能)やビッグデータなど、大量のデータを処理する際に用いられるクラスタはデータ群を指します。IoT(Internet of Things、モノのインターネット)の進展で収集できるデータは爆発的に増加しました。ビッグデータはイノベーションにつながる宝の山ともいわれますが、膨大なデータの解析は容易ではありません。そこで期待されているのがAIです。近年は機械学習と呼ばれるアルゴリズムの進化で、その可能性が大きく広がっています。
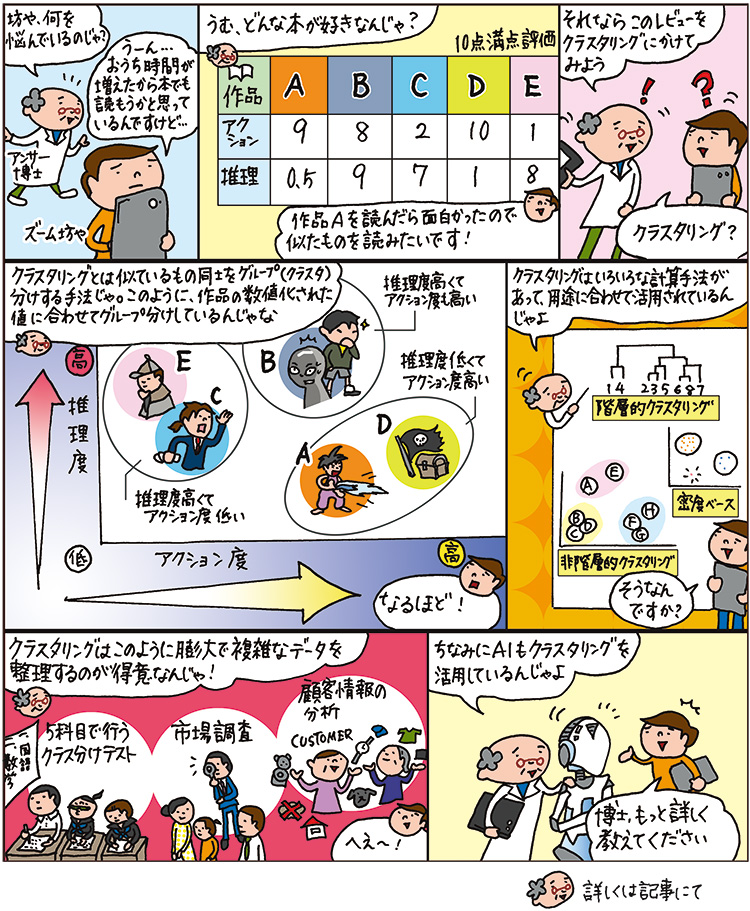
機械学習は二つに大別され、正解が分かっているデータ(教師データ)を基にルールやパターンを分析し、モデルを構築する「教師あり学習」と、教師データを与えずにデータの構造や特徴、類似性を学習させ、グループ分けを行う「教師なし学習」があります。例えば、猫の特徴を事前に学習させ、膨大な写真の中から、猫の写真を抽出させる場合は「教師あり学習」。一方、膨大な写真を読み込ませ、特徴の抽出から分類までを行わせる場合は「教師なし学習」となります。一見バラバラなデータを適切な群れに分類することでデータに意味が生まれ、有効活用につながります。
データを精度よく分類するために使われる三つの手法
クラスタリングの計算手法には3種類あります。
「階層的手法」は、階層構造を作りながら一つひとつのデータを比較して、類似度の高いまたは低いクラスタを、結合や分割を繰り返していく手法です。これはすべてのデータが分類されるまで繰り返され、目的に応じて好きな数にグループ分けをすることができ、最終的に枝分かれした一つのまとまりになったら完了となります。
「非階層的手法」は最終的なクラスタの数を先に決めてから、階層構造を作らずにデータが最適な分割となるよう探索していく手法です。計算量が階層的手法よりも少ないため、ビッグデータ解析に有効とされています。
「密度ベース手法」はデータ密度の高いところでクラスタを作り、離れたデータはノイズとして処理する手法。特異なデータの存在が明らかになるので、クラスタリングの精度向上が期待できます。
これらの手法の中でも広く用いられているのが非階層的手法で、特に「k-means法」はクラスタリングを代表する手法だといえます。このk-means法はk平均法とも呼ばれ、各データ点からクラスタの重心までの距離を基にクラスタの構成データを組み替えながら調整するアルゴリズムです。
学生の成績別クラス分けもAIを使えば簡単解決
k-means法がどのように活用できるのか、英語のクラス分けを例に説明します。
ある学校でリーディングとリスニングのテストを実施し、成績に応じて生徒を五つのクラスに分けることになりました。テストの平均点で分けることもできますが、リーディングだけが得意な生徒もいれば、リスニングだけが得意な生徒、どちらも同じくらいの成績の生徒もいます。
そこで、生徒たちの成績をk-means法で分類。縦軸をリーディング、横軸をリスニングとし、グラフに全員の点数をプロットすることで、クラスタを見いだすことができました。つまり、生徒たちを得意・不得意別に振り分けた五つのクラスタを明らかにし、学力が近い生徒同士のグループを作ることに成功したのです。
生徒数が少なければ、教師が手作業で計算することも可能ですが、生徒数が多い場合や、クラス分けに反映する科目の種類が多い場合などは、手計算では限界があります。このように膨大で複雑なデータを扱う際に、クラスタリングは有効な手法だといえます。
この事例では最終的なクラスタ数をあらかじめ決めていましたが、それが難しい事例も多くあります。クラスタ数をいくつに設定するかで結果も変わるため、決めるのが難しい場合にはまず任意のクラスタ数で計算したのち、それより多い場合や少ない場合を計算、比較しながら最適解に迫っていく手法を取ります。
目に見えない膨大な数の情報を分類し、活用するために有効な「クラスタリング」。AIを用いたビッグデータの分析分野の研究は、日々進んでいます。

この記事は2021年07月に掲載されたものです。