AI技術を活用したバルブ整備作業の工程改善
キーワード:バルブメンテナンス,AI,業務DX
バルブ整備作業の現場では,熟練作業者の高齢化による人員不足や技能伝承のための時間確保ができないといった問題があり作業の効率化が望まれている。そこで,従来手作業で行っていたバルブ整備レポート作成作業の一部にAI画像処理技術を導入し自動化することにより,作業効率を向上することに取り組んだ。この自動化による効果を検証するため,バルブ整備レポート作成支援のためのツールを開発し,ユーザ評価を実施した。その結果,バルブ整備レポート作成作業に要する工数を削減でき,人員不足への対応に加え,後継人材育成のための時間確保に貢献できる可能性を確認した。
1.はじめに
近年,熟練作業者の高齢化に伴い,生産や製造,整備を担う現場における技能伝承の重要性がますます高まっている。バルブ整備作業のような高度な専門知識と経験を要する業務においては,技能を有する人材の確保が困難となっており,この問題を解決するための新たな取り組みが求められている。
こうした背景のもと,我々は,自動化により効率化できる作業をみつけるために,バルブ整備作業の工程分析を行った。その結果,バルブ整備レポート作成作業に作業効率を向上できる余地が大きいと考え,この作業にAI画像処理技術を導入し自動化することにより,作業効率の向上に取り組んだ。本稿では,この取り組みの結果について述べるとともに,今後の展望についても示す。
2.バルブ整備作業の課題と改善への取り組み
2.1 バルブ整備作業の概要
バルブとは,液体や気体などの流体を制御し,配管内の圧力や流量を調整する役割を持つ機器であり,生産設備のプロセス制御において不可欠な役割を担う。バルブにトラブルが発生した場合,設備停止や品質低下,さらには事故や災害につながる可能性がある。また,バルブは生産設備ごとに異なる環境で稼働しているため,その状態も個体ごとに異なる。そのため,バルブの定期的な検査や整備が重要となる。
生産設備には多数のバルブがあり,これらすべてを一度に点検・整備することは難しい。この課題に対して,当社では,バルブ稼働データと当社ノウハウを組み合わせて,点検・整備するべきバルブを特定するための「バルブ解析診断サービス」を提供している。
点検・整備対象となるバルブが決まれば,整備工場にバルブ本体を引き取り,分解・点検を行い,必要に応じて部品の清掃・修理・交換を実施し,再組立を行って,整備を完了する。整備完了後は「バルブ整備レポート」を作成する。そのレポートには整備前後の部品の画像が記録されており,整備による変化を視覚的に把握できる。
2.2 バルブ整備作業の効率化の必要性
バルブ整備作業における現状として,作業者の高齢化により,これらの業務を担える人材が減少傾向にあり,後継人材の育成が急務となっている。ただし,単に人員を増やすだけではこの問題は解決しない。なぜなら,前述の整備作業における,バルブの分解・点検・修理・交換・再組立などの工程は高度な専門知識と豊富な経験が求められ,これらの技能を後継人材に伝承していくには,多くの時間が必要となるからである。
しかし,現在の整備作業の現場では,作業者が整備作業そのものに多くの時間を費やし,後継に技能の伝承をするような時間が十分に確保できていないのが現状である。このため,後継者不足の背景には「育成時間の確保が困難」という構造的な問題点が存在する。
このような状況下においては,一連のバルブ整備作業のうち,自動化が可能な作業については自動化を進め,知識や経験,技能を必要とする業務に関しては,後継人材の教育に必要な時間を割り当てられるようにすることが重要である。
2.3 バルブ整備レポート作成作業の自動化
バルブ整備作業の一連の工程のうち,自動化による工数削減可能な作業を探索した結果,バルブ整備レポート作成作業に着目した。
バルブ整備レポート作成作業は,バルブ整備現場で撮影された整備前後の部品画像とチェックシート画像を用いて,レポートを作成するものである。
部品の撮影時には,一連の部品画像がどのバルブに属するかわかるように,バルブ本体の情報(顧客名,事業所名,装置名,タグ名など)を記したチェックシートを撮影し,続いて,そのバルブの各部品を撮影する。
レポート作成時には,チェックシートごとに部品画像をグループ化し,各部品画像を目視で分類しながら,レポートに画像を貼付し,レポートを作成する。なお,整備前後の判別は画像の撮影時刻をもとに判断する。
上記の作業のうち,作業者が部品画像を目視で分類し,手作業でレポートに貼付する作業を自動化することで,現場の作業手順を大きく変えることなく,工数削減ができると考えた。
そこで,部品画像を自動的に分類するバルブ画像自動分類技術と,チェックシート画像の情報を自動的に読み取るチェックシート自動情報抽出技術を開発し,これらを統合してレポート作成を支援するツールの開発に取り組んだ。以降,各技術について記す。
3.バルブ画像自動分類
3.1 バルブ画像自動分類の問題
バルブ画像自動分類は,図1に示されるような整備現場で撮影された部品画像に対して,それぞれがどの部品に該当するかを自動的に判別する技術である。この技術を実用レベルで構築するためには,以下の問題を解決する必要がある。
- (1) 部品形状の構造識別:バルブ部品は形状が複雑で,別種の部品同士であっても局所的な特徴の差異が少ないため,部品構造のような大域的な特徴を捉えた識別が必要となる。
- (2) 撮影条件のばらつき:撮影画像は照明条件や撮影角度が一定ではなく,画像特徴量の変動により分類精度が低下する可能性がある。
- (3) 背景の影響:撮影画像には,工具や作業台などが背景に映り込む場合がある。背景に影響されない識別が必要となる。

図1 バルブ部品画像の例
3.2 採用した手法
バルブ画像自動分類を実現するため,深層学習を用いた画像分類手法を採用した。図2に学習過程と推論過程に関する処理フローを示す。学習過程では,撮影された部品画像とその正解情報からなる学習用データセットを構築し,これを用いて画像分類モデルを学習させる。推論過程では,学習済みの画像分類モデルを用いて,部品カテゴリが未知な画像に対して分類を行う。
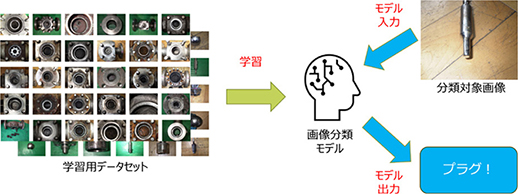
図2 バルブ画像自動分類の処理フロー
深層学習による画像分類モデルとしては,CNN(Convolutional Neural Network)が広く利用されている。CNNは畳み込み演算により局所領域から特徴を抽出し,それらを階層的に統合することで画像の理解を実現する。この構造により高い認識性能が達成されている。しかし,対象の形状や配置に関する大域的な変化や,要素間の依存関係の表現が十分でない場合がある。
前述のとおり,バルブ部品画像は局所的な特徴の差異が小さいため,CNNによる分類は困難であると考えられる。
こうしたCNNの構造的課題を克服するために,ViT (Vision Transformer(1))が提案されている。ViTは,自然言語処理分野で開発された Transformer(2)を画像処理に応用したものであり,入力画像を複数の領域画像に分割し,Multi-Head Attentionに基づいて各領域画像間の関係性を学習することで,画像特徴を大域的に捉えることを可能としている。
図3にViTの全体構成を示す。ViTは以下の主要な構成要素から成る。
- (1) 入力生成部:入力画像を一定サイズの領域画像に分割し,それぞれを一次元ベクトルに変換する。
- (2) 特徴抽出部:事前学習済みの特徴抽出モデルを用いて,各領域画像の特徴量を抽出する。
- (3) 分類部:特徴抽出部から得られたViT特徴量に対して,各認識タスクに応じてファインチューニングされた分類モデルを用いて,最終的な分類結果を出力する。
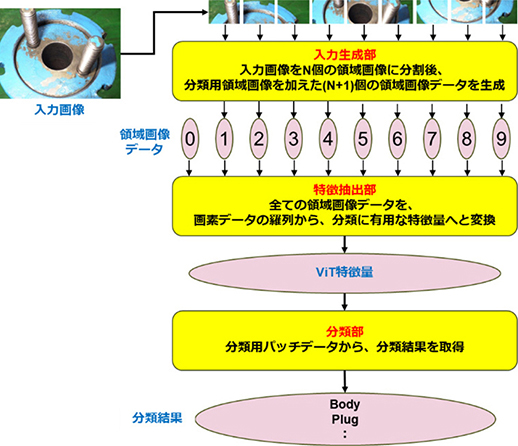
図3 ViTの全体構成
3.3 採用した手法の精度評価
3.3.1 ファインチューニング/テストデータの準備
以下の手順でファインチューニングとテストのためのデータを作成した。
- (1) 図1に示すような,ファインチューニングデータとテストデータの元となる,正解情報付きバルブ部品画像の画像データセットを準備する。
- (2) 画像データセットを指定割合でファインチューニングデータとテストデータにランダムに分ける。
- (3) ファインチューニングデータの各カテゴリの画像枚数が均等になるよう,データ拡張(画像の回転や反転など)を行う。この処理により,学習時のカテゴリ間の認識精度の偏りを防ぎ,モデルの汎化性能を向上させる。
3.3.2 画像分類モデルの比較
画像分類性能を比較するために,表1に示すCNN型の分類モデルであるResNet(3),DenseNet(4)とViT(1)をベースモデルとして,サイト(5)から取得し,それぞれファインチューニングを行い,その正答率を比較した。なお,ファインチューニングおよびテストには,画像サイズを224×224に整えた16カテゴリ,1,376枚のデータを使用した。結果を表2に示す。
表1 各分類モデルの基本情報

表2 各分類モデルによる正答率
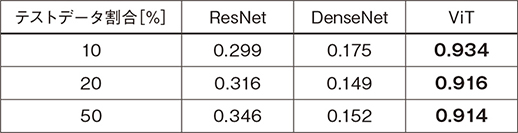
比較の結果,ViTは正答率90%以上であり,他の分類モデルより明らかに良好な結果を示し,今回対象とした画像データにおいては,ViTの優位性が確認された。
3.3.3 ViTのハイパーパラメタの選定
最適なViTのハイパーパラメタを選定するために,データセット(19カテゴリ,4060枚)のデータから75[%]をファインチューニングに,残りをテストデータに割り当てて,ハイパーパラメタ(モデル規模,領域画像サイズ,入力画像サイズ,追加学習の有無)の違いによる正答率の評価を行った。結果を表3に示す。
表3のモデル規模列の各項目はbase(約344[MB]), large(約1.2[GB]),huge(約2.4[GB])である。追加学習有無列は,ベースモデルが追加学習されているかどうかを表す。
表3 各種ハイパーパラメタの組み合わせによる正答率
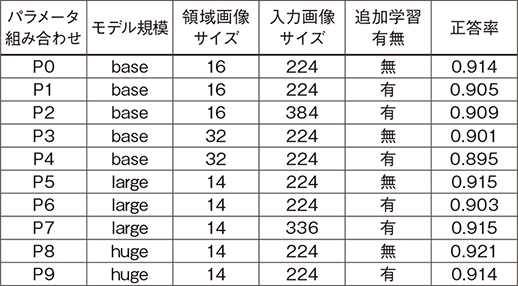
上記の結果より,各ハイパーパラメタには以下の傾向がみられた。
- (1) モデル規模:モデル規模は大きいほど精度は高くなるものの,大きな改善は見られない。
- (2) 領域画像サイズ:(P0,P3)(P1,P4)における正答率の比較より,領域画像サイズが小さいほど精度が高くなる傾向にある。
- (3) 入力画像サイズ:(P1,P2)(P6,P7)における正答率の比較より,入力画像サイズが大きいほど精度が高くなる傾向にあるが,その改善効果は微小である。
- (4) 追加学習有無:(P0,P1)(P3,P4)(P5,P6)における正答率の比較より,追加学習をしない方がより精度が高くなっている。
モデル規模が大きくなると,必要とされるハードウエアへの要求が高くなり,また処理時間も必要となることから,規模と分類精度のバランスを考慮して,baseを使用することにした。ここで,モデル規模がbaseで,最も精度の良いハイパーパラメタであるP0は,設計時に目標とした正答率90[%]以上を達成できているため,P0を採用した。
4.チェックシート自動情報抽出
4.1 チェックシート自動情報抽出の問題
チェックシート自動情報抽出は,図4に示すようなチェックシート画像から,顧客名,事業所名,装置名,タグ名などの情報を自動的に読み取る技術である。整備工場で撮影されるチェックシートには,以下のような問題があるため,これらの問題を解決する必要がある。
- (1) 撮影条件のばらつき:チェックシート画像は撮影角度が固定されておらず,位置が画像内で変動する。
- (2) 撮影画像の品質:実際の撮影では,ピンボケやノイズなどにより画像品質が低下する場合があり,認識精度をさらに悪化させる。

図4 チェックシート画像の例
4.2 開発した処理フロー
QRコードの認識には高い画質の画像が必要となるが,一度認識されれば,得られた情報の信頼性は高い。一方,文字認識による情報抽出は,“1”と“I”のような紛らわしい文字による誤認識はあるものの,QRコードを認識できないような低い画質の画像からでも情報が抽出できる可能性がある。
前節で述べた問題と上記の特徴を踏まえ,チェックシート自動抽出の問題(1)に対しては,チェックシートの撮影範囲,角度,明るさなどに対して,撮影ルールを決めることで対応した。また,チェックシート自動抽出の問題(2)に対応するために,画像処理によって画質の改善を段階的に実施しながら,情報抽出精度が高いQRコードの利用を優先し,最後に補完方法として文字認識を使用する方針とした。図5に開発した処理フローを示し,以下に各処理内容について記す。
- (1) 撮影画像からQRコード読み取り:QRコード認識ライブラリpyZBAR(6)を用い,撮影画像から直接QRコードを認識し,情報抽出が成功すれば処理終了。
- (2)撮影画像から領域群抽出:回転や拡大に強い局所特徴量AKAZE(7)を用いて,テンプレート画像との位置合わせを行い,QRコード領域と文字領域で構成される領域群を抽出する。
- (3)領域画像(改善前)からQRコード読み取り:QRコード領域からQRコードを認識し,情報抽出が成功すれば処理終了。
- (4)領域画像群の画質改善:ピンボケの画質劣化を改善する技術NAFNet(8)を用いて,QRコード領域と文字領域に対して画質改善を実施。
- (5)領域画像(改善後)からQRコード読み取り:画質改善されたQRコード領域からQRコードを認識し,情報抽出が成功すれば処理終了。
- (6)領域画像(改善後)から文字認識:文字認識ライブラリEasyOCR(9)を用いて,画質改善された文字領域から文字認識を実施する。文字認識の成否にかかわらず,この時点で処理を終了する。
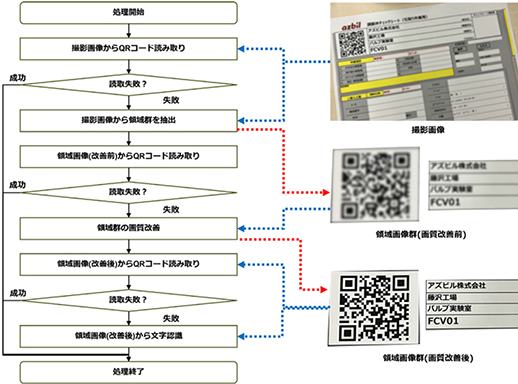
図5 チェックシート自動情報抽出の処理フロー
4.3 開発した処理フローの効果検証
開発した処理フローの効果を確認するため,図4に示すような画質が良いチェックシート画像に加え,図6に示すような様々な要因(ピンボケ,ノイズ等)で画質が悪いチェックシート画像を用いて,チェックシート自動情報抽出の成否結果を見ることにより,効果検証を行った。
検証の結果,単体のQRコード認識や文字認識では自動情報抽出が困難であった劣化画像に対しても,開発した処理フローでは自動情報抽出が可能であった。

図6 劣化チェックシート画像の例
5.バルブ整備レポート作成支援の取り組み
5.1 バルブ整備レポート作成支援ツールのフロー
前述のバルブ画像自動分類とチェックシート自動情報抽出を活用し,バルブ整備レポート作成業務を支援する枠組みを考案した。図7にその処理フローを示す。
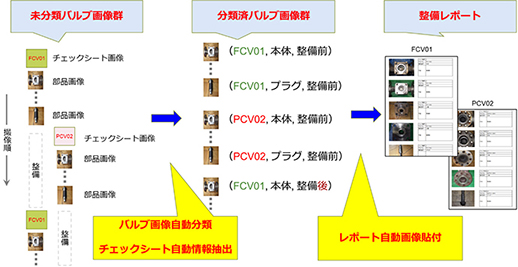
図7 バルブ整備レポート支援の処理フロー
上記の処理フローにおいて,従来は目視で行われていた撮影画像の整理や帳票への貼付などの作業を自動化するバルブ整備レポート作成支援ツールを開発した。図8にツールの画面イメージを示す。
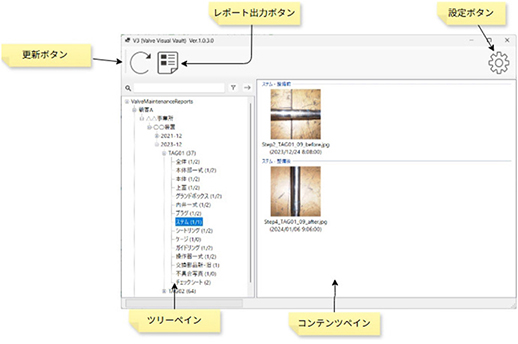
図8 作成したツールの画面イメージ
ツールを導入した一連の作業は以下の手順で行われる。
整備前後に,作業者はチェックシートと各部品を撮影する。
整備作業完了後のレポート作成時,作業者は主にツールを用いて作業を行う。
ツールは,撮影された画像のバルブ画像自動分類を行い,各画像が部品画像かチェックシート画像かの分類を行う。チェックシート画像に分類された画像に対してはチェックシート自動情報抽出を実施する。ここまでの処理で,バルブ画像自動分類やチェックシート自動情報抽出の結果に誤りがあった場合,ツールの画面上で修正を行う。
次に,上記の画像の整理結果をもとに,所定のフォーマットに従って画像貼付と属性記述を自動的に行い,作業者が修正可能な形式でレポートを出力する。
最後に,出力されたレポートに対して,作業者が人手でしか記述できない情報(整備所見など)を追記し,レポートを完成させる。
5.2 バルブ整備レポート作成支援ツールの評価
バルブ整備レポート作成支援による工数削減の効果を確認するため,国内外のバルブ整備作業者にツールを試用してもらい,所感や改善要望などの情報を収集した。
作業者10人を対象に,アンケート(選択式15問,自由記述1問)を実施し,集計した回答結果からツール導入効果を分析した。
5.2.1 工数削減効果について
ツールによる工数削減効果のアンケート結果を図9に示す。バルブ一台あたりにかかる作業時間は,従来の人手による画像分類や画像貼付の作業と比較し,平均約19%の工数削減が見込まれることが判明した。従来1件のレポート作成には平均約24分の工数を要していたため,1件当たりの削減時間は約4.5分となる。これは,全国で年間バルブ10,000台を整備したとすると,全体で約750時間の削減ができることになる。
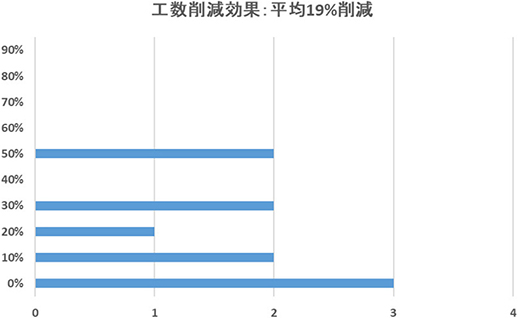
図9 アンケート回答結果
(ツールによる削減時間について)
5.2.2 ツールの改善要望と今後の対応
ツールの改善要望として以下のような項目が挙げられた。
- (1) バルブ画像自動分類の精度向上
- (2) 画像分類完了の待機時間の低減
(1)の「バルブ画像自動分類の精度向上」については,技術検討時は,自動分類精度が目標の90%を達成していたが,回答結果からすると,ツール試用時に分類精度が下がった可能性がある。
これについては,誤分類された画像を蓄積し,その画像を用いて再度ファインチューニングを行うことで分類精度の向上を図る方針である。
(2)の「画像分類完了の待機時間の低減」とは,1台のPCでまとめて画像分類処理を実行するために発生する数分程度の待機時間をなくしてほしいという要望である。この要望に対して,スマートフォンで撮影した画像をクラウドプラットフォームで逐次処理し,待機時間を解消することを検討している。
6.おわりに
本稿では,バルブ整備レポート作成作業にAI画像処理技術を導入し,自動化を行うことによる工程改善の取り組みについて紹介した。この取り組みにより工数削減を実現した。今後は,自動分類精度の向上,画像分類の完了待機時間の解消など,ユーザの要望に対応していくことで,更なる効率化の実現を目指す。また,ここで開発した技術の適用範囲を生産や製造,整備など他の現場に適用拡大することで幅広い業務改善につなげていきたい。
これらの取り組みを通して,単なる作業効率化にとどまらず,人員不足への対応や,後継人材への技能伝承に必要な時間を確保することなど,現場が抱える課題の解決につながることを期待する。
<参考文献>
(1) Dosovitskiy,A.:An image is worth 16x16 words: Transformers for image recognition at scale, arXiv,2020,arXiv:2010.11929
(2) Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L., Gomez,A.N.,Kaiser,Ł.,Polosukhin,I.: Attention Is All You Need,Advances in Neural Information Processing Systems,2017,Vol.30, pp.5998–6008,MIT Press
(3) He,K.,Zhang,X.,Ren,S.,Sun,J.:Deep Residual Learning for Image Recognition,Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2016,pp.770–778, IEEE
(4) Huang,G.,Liu,Z.,van der Maaten,L.,Weinberger,K.Q.:Densely Connected Convolutional Networks,Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017,pp.4700–4708,IEEE
(5) Hugging Face,Inc.:Hugging Face Official Website,2025,https://huggingface.co,(Accessed: 2025/10/01)
(6) Johnston,L.:pyzbar:Python library for reading barcodes and QR codes,2018,https://github.com/NaturalHistoryMuseum/pyzbar,(Accessed: 2025/10/01)
(7) Alcantarilla,P.F.,Bartoli,A.,Davison,A.J.:Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces,British Machine Vision Conference(BMVC),2013,pp.1–11,BMVA Press
(8) Chen,L.,Chu,X.,Zhang,X.,Sun,J.:Simple Baselines for Image Restoration,European Conference on Computer Vision(ECCV),2022, Springer
(9) Jaided AI:EasyOCR:Ready-to-use OCR with 80+ Languages Supported,2020,https://github.com/JaidedAI/EasyOCR,(Accessed: 2025/10/01)
<商標>
QRコードは株式会社デンソーウェーブの登録商標です。
<著者所属>
細居 智樹 アズビル株式会社 AIソリューション推進部
大枝 賢 アズビル株式会社 サービス本部サービス技術部
この記事は、技術報告書「azbil Technical Review」の2026年04月に掲載されたものです。