〜人工知能分野の国際会議AAAIに採択された技術〜
高性能で軽量な変化検知技術の異常検知への応用
〜人工知能分野の国際会議AAAIに採択された技術〜
キーワード:AIによる異常予兆検知,AI異常予知
産業機械の重故障から軽故障まで広く適用可能であり未経験の異常状態も含め検出が可能な新しい変化検知技術について論じる。この技術はセンサデータなどの対象機器のデータを事前に学習することが不要であり,アルゴリズムを実行する計算機環境とセンサデータさえあればすぐに利用することが出来る。利用にあたっては大きな計算機資源を必要としない,またアルゴリズムの実行処理速度が比較した他の技術と比べて高速であるので計算機システムで本アルゴリズムを実行した際には多くのセンサデータに対して異常状態となる変化を検出することが可能である。
1.はじめに
AI(artificial intelligence)の発展および計算機の技術革新によりモバイル端末において,SNSにおけるコミュニケーション内容の多言語へのリアルタイム翻訳やスケッチの提示や自然言語によるコンセプト提示からの画像や動画の生成など高度なAI処理が実現されつつある。産業応用に注目すると,高度な深層学習による異常検知技術の開発と製造現場への応用も始まっている(1)。一方でこれらの先端的な技術の利用が困難な場面が多々存在する。産業機械においてはその構造や原理が何十年にもわたり変化がなく,また技術革新も行われないものが多い。しかし社会的ニーズから必要とされるので同じ構造で生産され使用され続ける。これらの産業機械は異常検知の仕組みがなく,異常であることを把握するにはヒトが産業機械の前に行き機械が動作しているか停止しているかを五感で判断するケースもある。このように本来動作すべき機械が停止している重故障の場合は異常であることを判断しやすいが,機械は一見正常動作しているように見えて,機械内部に異常が発生している場合がある。例えば,積算値の表示(計測値や計量値の積算値)の進み方が正常時と比較してわずかに遅いもしくはわずかに速い軽故障が発生していることがある。このような軽故障を検知するにはヒトの五感に依らないデータに基づく異常検知方法が求められる。
本論文ではレガシー産業機械にもすぐに適用でき,異常検知が可能な新しい変化検知技術を提案する。また,最新の産業機械において既に高度な異常検知技術を採用済みの場合でも,協調的にこの変化検知技術を組み入れることが出来,異常検知の更なる高度化が可能であることについて述べる。
なお本論文で紹介する変化検知技術はAI,人工知能分野のトップ国際会議「AAAI 2025」で論文採択された技術である。AAAIはNeurIPS,CVPR,ICLRと並ぶAI分野の主要国際会議で,全体の投稿数は1万件を超え,採択率は20〜30%程度。日本からの論文投稿に対する採択率は数%程度である(2)。
2.関連技術
JIS Z9021 シューハート管理図と呼ばれる時系列データの異常値管理の方法が長年にわたって我が国の製造現場において利用されてきた。図1は弊社の時系列データの異常値管理ソフトウエアの画面例である。画面中段にWECOルール(Western Electric rules)による異常値管理画面がある(3)。
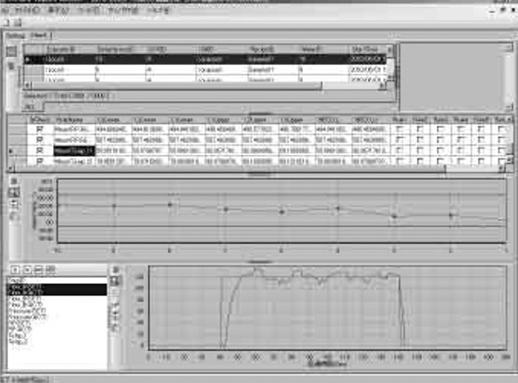
図1 SPC(Statistical Process Control)管理の例
山縣 et al.(2011)から引用
これは管理対象データが正規分布に従うとしグラフの縦軸中央をデータの平均,グラフの上と下に管理限界値を設定しその値を超えた回数によって異常が発生しているかを判断する手法である(4)。異常判定のアルゴリズムと管理限界値についてはJIS Z9021に規定されている。WECOルールは管理対象データが正規分布に従う限りは簡単なアルゴリズムであるにもかかわらず十分に異常値管理を行うことが出来る。一方,管理対象データが正規分布に従わない場合はこのアルゴリズムを適用することは出来ない。
WECOルールは簡単なアルゴリズムで異常値管理を実施できるのが特徴である。一方,複雑なアルゴリズムを用い大規模な計算機資源を使って異常検知を行う技術も存在する。例えば,NRAF(Nonlinear Regression Analysis using FNN, FNN: Fuzzified Neural Network)はデータから学習モデルを生成し,複雑なデータに対しても高精度な異常検知ができることを特徴とする技術である(5)(6)。データを学習する都合,データがある確率分布に従うことは想定するが正規分布に従うことまでは要求しないので適用範囲はWECOルールと比べ広範囲に及ぶ。
3.提案手法
3.1 変化検知とは
最初に本論文の表題にもある変化検知について説明する。時系列データがある確率分布に従うとき,その時系列データが別の確率分布に従うようになった時点を変化が発生したと定める。本節では確率分布の変化として平均だけを取り上げるが,提案する変化検知手法は他の統計量の変化も検出することが出来る。図2は正規分布に従う時系列データのグラフである。横軸Timeが200系列毎に平均値が変化。平均値\(\mu\)は\(\mu\)=2,\(\mu\)=6と変化する。つまり図2の横軸Timeが200,400,600・・・の時点で確率分布が変化している。変化検知とはこの横軸Timeが200,400,600・・・の時点での変化を捉えることである。
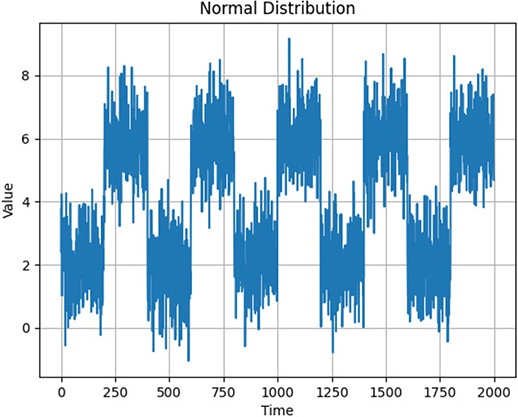
図2 正規分布の平均値を200系列毎に変化させたグラフ
図2のデータに2.関連技術で述べた山縣 et al.(2011)を適用した場合を考える(3)。データは正規分布に従うので横軸Timeが0から199までの区間において管理限界値を設定しこの区間を正常区間とした場合,横軸Timeが200から399までの区間は0から199までの区間と比べ平均値が異なる。先に設定した管理限界値を超えるデータが発生しているので異常が発生している区間となる。 山縣 et al.(2011)による異常検知は異常の有無や異常が発生している区間を捉える技術であり,本論文における変化検知はデータがある確率分布に従う場合,図2の横軸Timeが200,400,600・・・の時点で異なる確率分布になった時点を捉える技術である(3)。
まとめると変化検知は異常となっている区間の始まりやデータ部位を見つける問題と捉えることが出来る。これを異常部位検出(discord discovery)と呼ぶこともある(7)。
3.2 関連技術が苦手とする問題例
最初に時系列データが正規分布に従わない場合の2.関連技術の異常検知と本論文における変化検知について論じる。図3は横軸Timeが200系列毎に自己回帰モデルのパラメータ\(\mu\)が\(\mu\)=2と\(\mu\)=6の間で変化する。
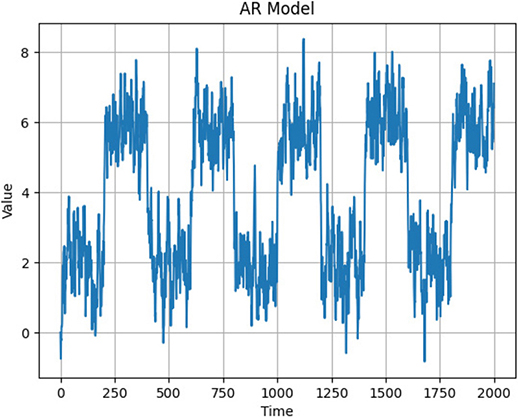
図3 自己回帰モデルの平均値を200系列毎に変化させたグラフ
山縣 et al.(2011)はデータの確率分布が正規分布であることを想定した異常検知であるので正規分布以外の時系列データに対して適用することは想定されていない(3)。一方,本論文における変化検知はデータの確率分布に寄らず適用可能である特徴を持つ。
木村 et al.(2016),青田 et al.(2024)はデータの確率分布を限定する手法ではなく,複雑なデータに対しても高精度な異常検知が行える(5)(6)。しかし異常検知を行うためにはデータを学習し学習モデルを生成する必要がある。一方,本論文における変化検知はデータを学習し学習モデルを生成する必要はない。つまり時系列データに対してデータを学習する時間を要することなく,すぐに変化検知を実行できるのが特 徴である。
3.3 変化検知アルゴリズム
本節ではThe 39th AAAI Conference on Artificial Intelligence(AAAI)で採択された変化検知技術について平易な説明を試みる。内容の詳述についてはSuzuki et al.(2025)を参照されたい(8)。

図4 変化検知アルゴリズム
図4は変化検知技術の処理手順(アルゴリズム)である。以下に図を交えながら説明する。
図5は変化検知アルゴリズムへ入力する時系列データの例である。グラフは時刻tにおけるデータ値\( \zeta\)を表す。この例では時刻t=100,データ値\( \zeta\)がPの前後でデータの確率分布が変化した。つまり変化検知アルゴリズムが検出すべき変化が発生した。
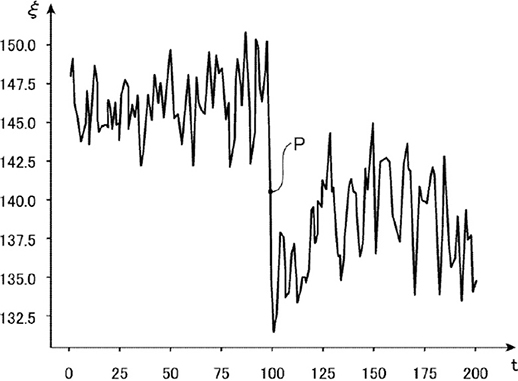
図5 変化検知アルゴリズムへ入力するデータ例
図6は時系列データをスライド窓によりベクトルデータ化する様子である。隣接するM個のデータをM次元のベクトルとして抽出する。スライド窓をデータに沿ってスライドすることで複数のM次元ベクトルに変換する。図6はスライド数を1とした例である。本論文の説明では変化検知アルゴリズムのスライド数は1,M=10とする。スライド窓によるベクトルデータ化については井手 et al.(2015)を参照されたい(7)。

図6 スライド窓により時系列データをベクトルに変換
本節の以下に使用する図は説明を容易にするためにM=2の場合とする。図7はM=2として図6の時系列データからベクトルに変換した複数ベクトルをグラフにプロットした例である。変化検知アルゴリズムに入力されたデータは図5でありデータPの前後で変化が発生している。図7においてはデータPの前後はグラフの●(グラフの右上)と×(グラフの左下)で表される。
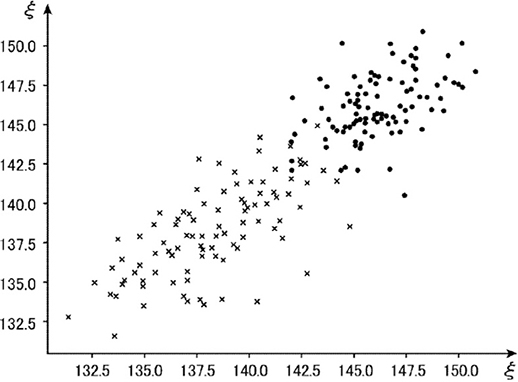
図7 図6のM=2ベクトルをグラフにプロットした例
図8左はデータP前後のベクトルVに対して図7の×(グラフの左下)から●(グラフの右上)へのベクトル(差分ベクトルと呼ぶ)を求めた例である。×から最も近い●を抽出。その後,k近傍法により複数の●のグループ(クラスタ)から重心を求めその重心に対して×から向かうベクトルを計算する。図8左はk近傍法を適用する前の様子である。この得られたベクトルを差分ベクトルと呼ぶ。

図8 確率分布に変化がある時の差分ベクトルの取得と正規化後の様子
図8中央は得られた複数の差分ベクトルの様子である。ベクトルの向きと大きさは異なる。次に差分ベクトルの正規化処理を行い大きさ1に変換する。図8右は正規化後の差分ベクトルの様子である。図8は分かりやすく説明するためにM=2とし半径1の円周上に分布する様子を示す。実際の変化検知アルゴリズムはM=10なので次元数10の超球面上に分布する。
図9は図8に対して変化検知アルゴリズムへ入力する時系列データに図5のデータPの前後の様な確率分布の変化がない場合の差分ベクトルの正規化後の様子である。差分ベクトルの方向は偏りが小さく正規化後の複数の差分ベクトルは円周上に均一に近い形で分布する。
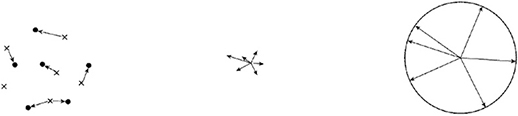
図9 確率分布に変化がない時の差分ベクトルの取得と正規化後の様子
図10は,図9までに説明した内容を,今度は図7の●から×に対して実施し差分ベクトルを求める手順を示したものである。つまり図8の説明と同じ処理を●から×に対して行う。
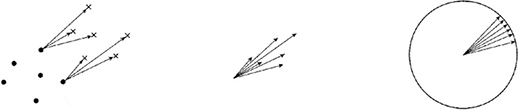
図10 ●から×に対して差分ベクトルの取得と正規化
複数の正規化後の差分ベクトルの分布の偏りはそれぞれ図8の場合と図10の場合で算出する。算出方法はレイリースコア(Rayleigh Score)を用いた(9)。レイリースコアは正規ベクトルが超球面上において分布が均一(一様)である場合にはゼロに近い値になり分布に偏りがある場合には正の大きな値になる(9)。このためレイリースコアの大きさを評価することで時系列データに変化があったか否かを判定することが可能となる。図8と図10でそれぞれ算出されるレイリースコアを比較して,値が大きい方のレイリースコアを最終的な変化検知のスコア値として選択する。
4.実験結果
実際の産業機械の内部によく使用されているタイミングギアの劣化が発生したシナリオを想定し,産業機械に取り付けられた振動センサーの値を変化検知アルゴリズムへ入力したときの実験結果について説明する。
図11はタイミングギアの模式図である。タイミングギアは二つ,それぞれG1とG2がかみ合うようになっている。タイミングギアの劣化は摩耗,傷,欠け,異物の付着等によって起こる。これらにより振動が発生もしくは変化するため,タイミングギアから発生する振動の変化を検出することでタイミングギアの故障や異常を検出することが出来る。
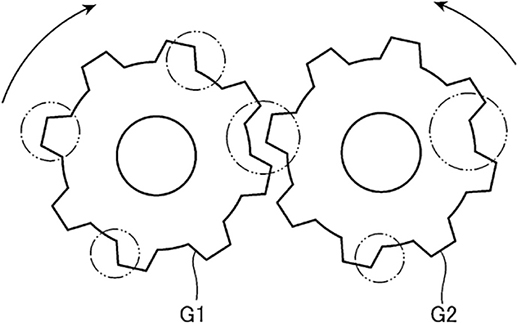
図11 産業機械のタイミングギアの例
図12はあるサンプリング周期でタイミングギアG1およびG2から発生する振動をセンサーにより取得した振動レベルのデータである。図11のタイミングギアG1およびG2の○で囲ったギア歯の箇所に異物を付着してタイミングギアの劣化を模擬した。
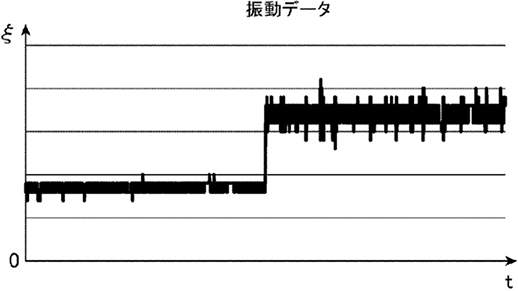
図12 タイミングギアの振動データ
図13は変化検知アルゴリズムに図12の振動データを入力し算出した変化スコアの推移である。図12の振動データの振動レベルが大きく変化した時刻に変化スコアが最大になっている。
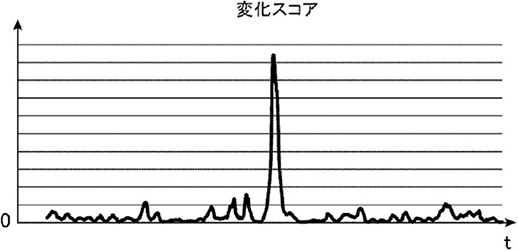
図13 タイミングギアの変化スコア
5.複雑なデータへの適用例
本論文の変化検知技術をYamanishi et al.(2002)が実データを使った変化検知の標準問題として実施した株式指数(TOPIX, Tokyo stock price index)に対して適用してみる(10)。取引市場においてはたびたび潮目と呼ばれる取引参加者における投資行動の変化が確認されている。図14の様な東証株価指数(TOPIX)の日次の終値の階差を取った後,変化検知アルゴリズムへ入力する。従来の株価の研究においては,株価の変動(ボラティリティ,階差の大きさ)そのものが着目されることが多いが,変化検知アルゴリズムはこれらの変動の大きさをそのまま変化の大きさとして扱うわけではない(図15)。

図14 1985年から1995年の東証株価指数(TOPIX)の日次の終値
株式市場における潮目と呼ばれるイベントは多々あるがここではよく知られたバブル景気を取り上げる。バブル景気の期間は1986年12月から1991年2月までと言われており,岩田(2005)で示されている(11)。この示された日付の近傍で図15を見ると変化スコアが1986年11月5日と1990年12月20日でスコア値が大となっており,変化検知アルゴリズムが変化を検出したことを表している。これは実証研究的な株価研究における一般的なバブル景気の開始時期よりも株式市場の変化を早く検出し,一般的なバブル景気の終了時期よりも株式市場の変化を早く検出していることを示している。
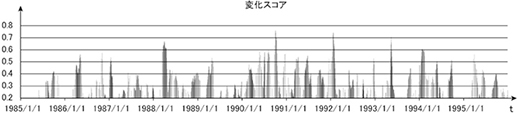
図15 東証株価指数(TOPIX)の変化スコア
株式指数(TOPIX, Tokyo stock price index)の変化検知は図12のタイミングギアの振動データよりも複雑でありデータの確率分布を事前に把握することは困難であるにも関わらず変化検知アルゴリズムは未知の確率分布に従うデータに対して変化を検出した。このことから筆者らは本論文の変化検知技術は複雑な実世界における産業機械のセンサデータに対しても異常となる変化を検出できる可能性があると考える。
6.異常検知技術への応用
6.1 他の手法との共存
本論文の変化検知アルゴリズムはそれ単独でも使用できるがアズビルがすでに保有している数々の異常検知技術と併存可能な点について述べる。
図16は村上 et al.(2020)において複数の予測モデルを並列的に使用することで予測精度が向上可能であることを示す概念図である(12)。この例では図の下から入力される燃料ガスの使用量(青色でプロットされたグラフ)をHeuristic,Linear Model,Nonlinear Modelの3つの予測器に分配し,それぞれの予測器は燃料ガス容器が空になる日時を予測する。予測情報利用者の効用の中身により,1)容器内の燃料ガス切れリスクを最大限回避したい場合は一番早い日時でガス切れを予測した予測モデル結果を採用,2)総合的に容器内の燃料ガス切れを予測したい場合は3つの予測器が出力するガス切れ日時の平均を計算し採用,などが考えられる(13)。採用された燃料ガス容器が空になる日時を図16の図の上のグラフ(赤色でプロットされたグラフ)に出力する。
この考え方をアズビルの異常検知に取り入れると,図16の下のグラフは異常を検出したい対象機器の振動などのデータが該当する。図中のHeuristic,Linear Model, Nonlinear Modelは本論文の変化検知アルゴリズムおよび山縣 et al.(2011),木村 et al.(2016),青田et al.(2024)などが該当する(3)(5)(6)。複数の異常検知および変化検知アルゴリズムにより検出された結果を多数決などの方法により統合し図16の図の上のグラフに出力する。この時,グラフの形は図16と異なることが予想される。
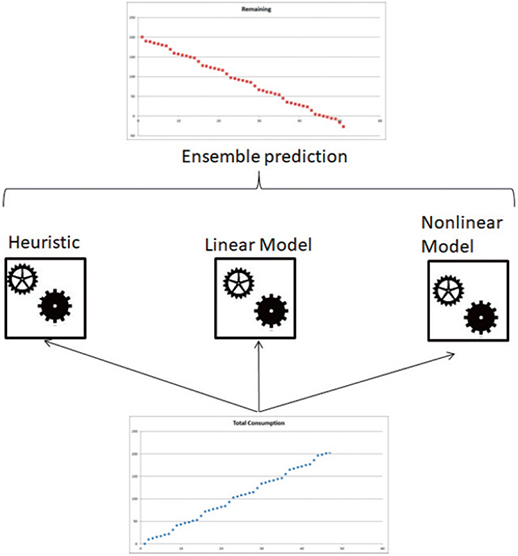
図16 アンサンブル学習の概念図
6.2 本手法の採用容易性
論文の変化検知技術についてアズビルの産業機械への適用やアズビルが保有する異常検知ソリューションへの採用の容易性について述べる。
最初にプログラムの実装について,仮に図4の処理手順(アルゴリズム)をPythonでプログラミングした場合Pythonの標準に対して数値計算拡張モジュールNumPyのライブラリ使用を要求する程度で実行が可能である。つまり最新のAI処理で頻繁に利用され深層学習に代表されるニューラルネットワークを使うためのライブラリは不要である。このことからプログラムのバイナリコードを産業機械のローカルCPU上で実行する際に気になるROM化されるファイルサイズは深層学習による異常検知技術と比べ非常に小さなファイルサイズとなり,小規模な計算機資源である産業機械のローカルCPUで実行するのに適している(1)。
次にプログラムの実行処理時間について,Suzuki et al.(2025)は本論文の変化検知技術と他の手法の比較を行った(14)(15)(16)(17)。代表的な他の4つの手法との間で同一の産業機械のセンサデータに対して各アルゴリズムがデータ上の異常となる変化を検出するまでの処理時間を計測した(8)。その結果,本論文の変化検知技術が0.5秒で処理が終了するのに対して最も処理が軽いHooi et al.(2019)は1.1秒を要し,最も処理が重いニューラルネットワークを使ったChang et al.(2019)においては216秒を要した(15)(17)。つまり本論文の変化検知技術は他の4つの手法と比較して最も高速に処理できた。よって本論文の変化検知技術は同一計算機資源で実行した他の4つの手法と比べて処理時間が短い(処理が軽い)。このことからより多くのセンサデータに対して異常状態となる変化を検出することが可能となる。
7.おわりに
本論文の変化検知手法はデータに対する事前の学習が不要であり,データの確率分布も特に限定しない。処理速度は比較した他の変化検知手法と比べ高速であり,アルゴリズムの実行においては深層学習では必須となるGPUなど特別な計算機資源は必要としない。これらの特徴から他の異常検知と並列的に組み合わせて利用することが容易である。
本論文の変化検知手法は日本国と米国特許出願済みであり,今後は他の異常検知技術と組み合わせるなど,実用ソフトウエアへ向け引き続き技術開発を行っていきたい。
<参考文献>
(1) 曽我部 東馬,曽我部 完,Pythonによる異常検知,2021年,オーム社
(2) 鎌田久美,堀田継匡, 「人工知能分野及びロボティクス分野の国際会議における国別発表件数の推移等に関する分析」,文部科学省 科学技術・学術政策研究所 科学技術予測・政策基盤調査研究センター,2023年5月,https://nistep.repo.nii.ac.jp/records/6846
(3) 山縣謙一,黒澤敬,村上英治,製造データの超効率的解析による高収益精算への挑戦,azbil Technical Review,2011年, Vol.52, pp.76-81, アズビル株式会社
(4) Thomas P.R., Statistical Methods for Quality Improvement (Wiley Series in Probability and Statistics),2013,Wiley.
(5) 木村大作,山縣謙一,IoT時代のスマート設備管理を目指す創業ビッグデータを活用したオンライン異常予兆検知システムの開発,azbil Technical Review,2016年, Vol.57, pp.9-15, アズビル株式会社
(6) 青田直之,川瀬健,日暮優,小川勇馬,藤原圭祐,オンライン異常予兆検知システムの大規模プラント向け拡張機能の開発,azbil Technical Review,2024年, Vol.65, pp.21-25,アズビル株式会社
(7) 井手 剛,杉山 将,異常検知と変化検知 (機械学習プロフェッショナルシリーズ),2015年,講談社
(8) Suzuki,I.; Hara,K.; and Murakami,E,,Hubness Change Point Detection,2025, The 39th AAAI Conference on Artificial Intelligence(AAAI).
(9) Rayleigh,L.,On the problem of random vibrations,and of random flights in one,two,or three dimensions.1919,Philosophical Magazine,37(220):321-347.
(10) Yamanishi, K.; and Takeuchi, J.,A unifying framework for detecting outliers and change points from nonstationary time series data, In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2002,341-349, KDD.
(11) 岩田規久男,『日本経済を学ぶ』,2025年,筑摩書房〈ちくま新書〉
(12) 村上英治,土岐爽真,組合せ最適化手法によるLPガス容器配送方法とその効果,azbil Technical Review,2020年, Vol.61, pp.24-28,アズビル株式会社
(13) Samuelson,P.A.,Foundation of Economic Analysis,1947,Harvard Univ. Press,Cambridge.
(14) Liu,S.; Yamada,M.; Collier,N.; and Sugiyama, M.,Change-point detection in time-series data by relative density-ratio estimation,2013, Neural Networks.
(15) Hooi,B.; Faloutsos,C.,Branch and Border: Partition-Based Change Detection in Multivariate Time Series,2019,In Proceedings of the 2019 SIAM International Conference on Data Mining (SDM).
(16) Alanqary,A.; Alomar,A.; and Shah,D., Change Point Detection via Multivariate Singular Spectrum Analysis. In Ranzato,M.; Beygelzimer,A.; Dauphin, Y.; Liang, P.; and Vaughan,J. W.,eds., Advances in Neural Information Processing Systems,2021,volume 34,23218–23230. Curran Associates,Inc.
(17) Chang,W.; Li, C.; Yang,Y.; and P´oczos,B., Kernel Change-point Detection with Auxiliary Deep Generative Models. In 7th International Conference on Learning Representations,ICLR 2019,New Orleans,LA,USA,May 6-9,2019, 1–14. OpenReview.net.
<著者所属>
村上 英治 アズビル金門株式会社 経営企画部
鈴木 郁美 山形大学 理学部
原 一夫 山形大学 理学部
この記事は、技術報告書「azbil Technical Review」の2026年04月に掲載されたものです。